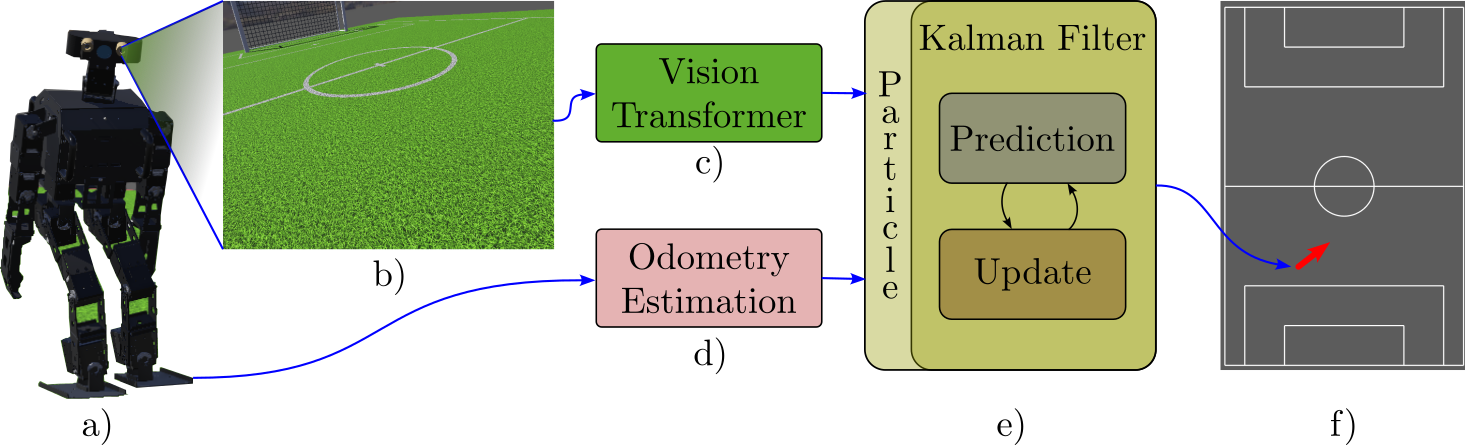
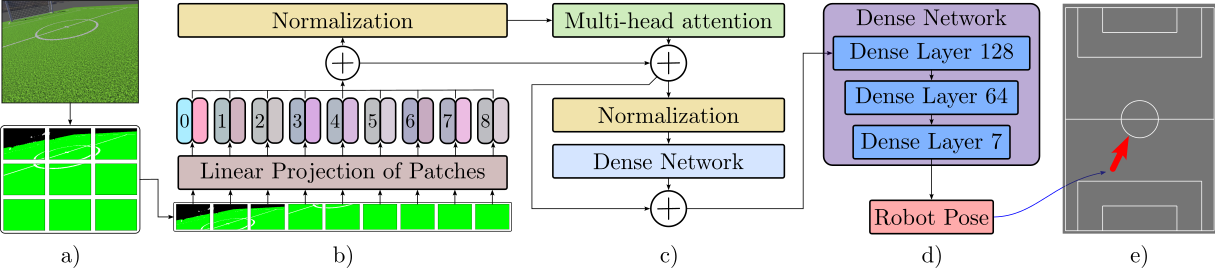
Vision Transformer Front‑End
Input RGB frames (224×224) are split into 16×16 patches and projected to a token sequence. Six Transformer encoder blocks with multi‑head self‑attention learn global field context. The CLS token passes through a regression head that outputs a 7‑D pose vector (quaternion + XYZ).
Hybrid UKF–MCL Back‑End
- Prediction: Dead‑reckoning from joint encoders & IMU updates each particle and UKF state.
- Update: High‑confidence ViT observations trigger a UKF update; ambiguous observations trigger an MCL reweight/resample, preserving multimodal beliefs.
- Switch Criterion: ViT output entropy & field symmetry inform the UKF↔MCL switch.
Algorithm: Hybrid Localization Update Per Step
Require: Image It, Odometry ut, Previous state st-1
1: ŝt ← ViT_Predict(It)
2: s̄t ← MotionModel(st-1, ut)
3: if Confidence(ŝt) > τ then
4: st ← KalmanUpdate(s̄t, ŝt)
5: else
6: st ← MCLUpdate(s̄t, ŝt)
7: end if
8: return st
Training & Sim‑to‑Real
15k synthetic frames collected in Webots with domain randomization (lighting, textures, camera jitter). The ViT is trained with Adam (LR 1e‑4, batch 64, 100 epochs) minimizing SSE on 6‑DoF poses, then fine‑tuned on real footage.